OpenVINO2025+QWen2.5-VL多模态大模型应用演示
 openlab_96bf3613
更新于 8月前
openlab_96bf3613
更新于 8月前
模型下载与转换
QWen-VL是主要是由QWen LLM、Vision Encoder、MLP-based Vision-Language Merger 三个组件组合完成的架构,完整的QWen-VL的架构图示如下:
当前支持Qwen/Qwen2.5-VL-3B-Instruct与Qwen/Qwen2.5-VL-7B-Instruct两个模型可供下载

huggingface-cli download "Qwen/Qwen2.5-VL-3B-Instruct" --local-dir qwen2.5_3b
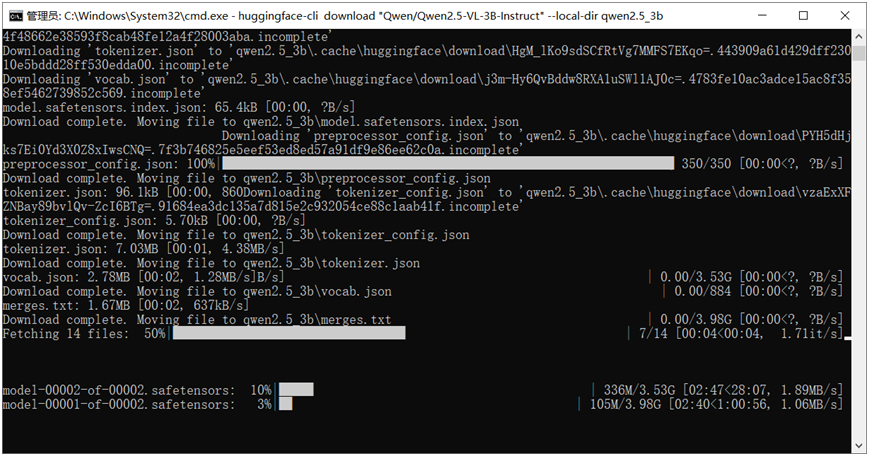
下载完成以后需要使用optimum-cli工具把模型转换为OpenVINO支持格式,命令行格式如下:
optimum-cli export openvino --model <model_id_or_path> --task <task> <output_dir>
需要安装一下NNCF这个工具,
pip install nncf -i https://pypi.tuna.tsinghua.edu.cn/simple
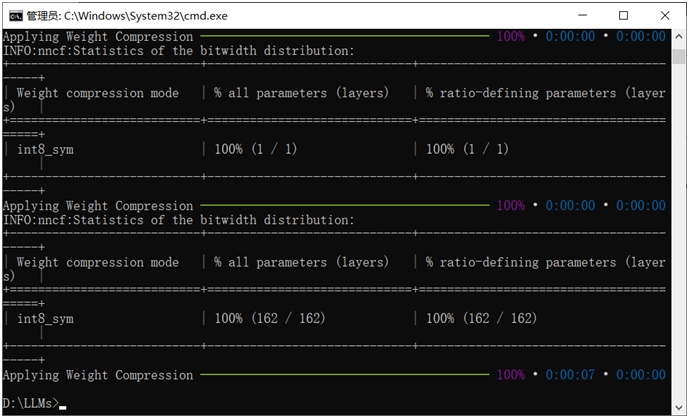
帮助把大模型压缩量化支持INT8、INT4模式文件。转换的命令行如下:
optimum-cli export openvino --model ./qwen2.5_3b qwen2.5_3b/INT4 --task image-text-to-text --weight-format int4
官方文档给出转换命令行 没有--task参数会导致转换时候报错,错误提示就是必须指定--task参数,QWen2.5-VL模型支持的task参数如下:
--task image-text-to-text
表示多模态输入支持图像与文本。
转换之后生成INT4格式的qwen2.5-openvino格式文件
推理SDK与演示
首先需要安装QWen API工具支持包
pip install qwen-vl-utils[decord]
安装好以后,然后通过optimum openvino的插件OVModelForVisualCausalLM 加载模型,基于QWen API函数构建输入预处理与输出后处理,最终实现的代码如下:
import cv2 as cv
from transformers import AutoProcessor, AutoTokenizer
from qwen_vl_utils import process_vision_info
from transformers import TextStreamer
from optimum.intel.openvino import OVModelForVisualCausalLM
min_pixels = 256 * 28 * 28
max_pixels = 1280 * 28 * 28
model_dir = "D:/LLMs/qwen2.5_3b/INT4"
processor = AutoProcessor.from_pretrained(model_dir, min_pixel***in_pixel****ax_pixel***ax_pixels)
model = OVModelForVisualCausalLM.from_pretrained(model_dir, device="CPU")
if processor.chat_template is None:
tok = AutoTokenizer.from_pretrained("D:/LLMs/qwen2.5_3b")
processor.chat_template = tok.chat_template
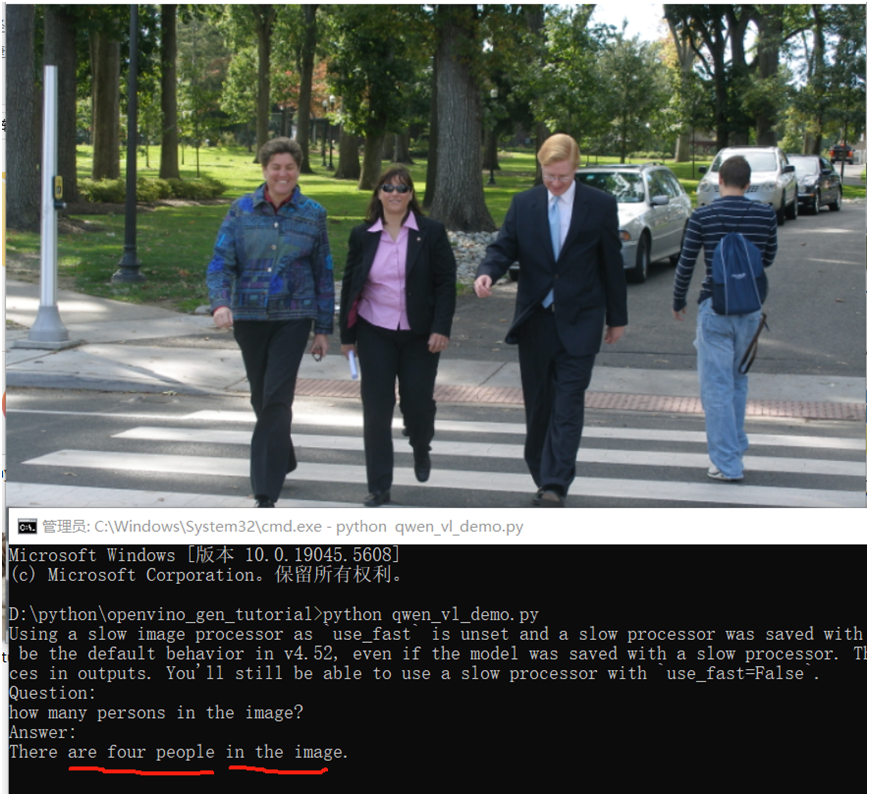
image = cv.imread("D:/pedestrian.png")
question = "how many persons in the image?"
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "D:/pedestrian.png",
},
{"type": "text", "text": question},
],
}
]
# Preparation for inference
text = processor.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
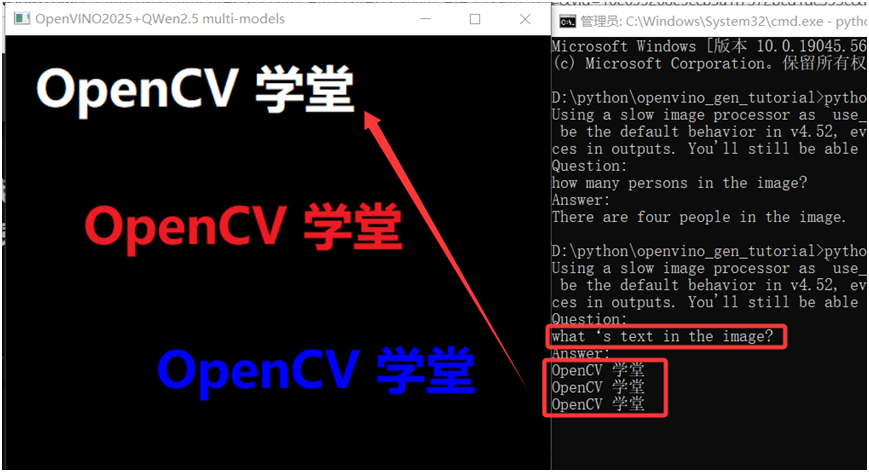
QWen2.5-VL 零样本的图像分类与内容检测演示
QWen2.5-VL OCR识别演示
OpenVINO+QWen2.5-VL大模型部署真香。
0个评论