利用OpenVINO™高效推理MiniCPM4系列模型
 openlab_96bf3613
更新于 10月前
openlab_96bf3613
更新于 10月前
模型介绍
今天,面壁智能正式发布端侧MiniCPM 4.0 模型,实现了端侧可落地的系统级软硬件稀疏化的高效创新。
面壁推出的MiniCPM 4.0系列LLM模型拥有 8B 、0.5B 两种参数规模,针对单一架构难以兼顾长、短文本不同场景的技术难题,MiniCPM 4.0-8B 采用「高效双频换挡」机制,能够根据任务特征自动切换注意力模式:在处理高难度的长文本、深度思考任务时,启用稀疏注意力以降低计算复杂度,在短文本场景下切换至稠密注意力以确保精度,实现了长、短文本切换的高效响应。
本文将介绍如何利用openvino-genai工具在本地部署MiniCPM 4.0系列模型。
内容列表
1. 环境准备
2. 模型下载和转换
3. 模型部署
第一步,环境准备
基于以下命令可以完成模型部署任务在Python上的环境安装。
python -m venv py_venv ./py_venv/Scripts/activate.bat pip install --pre -U openvino-genai --extra-index-url https://storage.openvinotoolkit.org/simple/wheels/nightly pip install nncfpip install git+https://github.com/huggingface/optimum-intel.git 该示例在以下环境中已得到验证:
· 硬件环境:
o Intel® Core™ Ultra 7 258V
§ iGPU Driver:32.0.101.6790
§ NPU Driver:32.0.100.4023
§ Memory: 32GB
o Intel® Core™ Ultra 9 285H
§ iGPU Driver:32.0.101.6790
§ NPU Driver:32.0.100.4023
§ Memory: 32GB
· 操作系统:
o Windows 11 24H2 (26100.4061)
· OpenVINO版本:
o openvino 2025.2.0-dev20250520
o openvino-genai 2025.2.0.0-dev20250520
o openvino-tokenizers 2025.2.0.0-dev20250520
第二步,模型下载和转换
在部署模型之前,我们首先需要将原始的PyTorch模型转换为OpenVINOTM的IR静态图格式,并对其进行压缩,以实现更轻量化的部署和最佳的性能表现。通过Optimum提供的命令行工具optimum-cli,我们可以一键完成模型的格式转换和权重量化任务:
optimum-cli export openvino --model openbmb/MiniCPM4-8B --task text-generation-with-past --weight-format int4 --group-size 128 --ratio 0.8 --trust-remote-code
开发者可以根据模型的输出结果,调整其中的量化参数,包括:
· --model: 为模型在HuggingFace上的model id,这里我们也提前下载原始模型,并将model id替换为原始模型的本地路径,针对国内开发者,推荐使用ModelScope魔搭社区作为原始模型的下载渠道,具体加载方式可以参考ModelScope官方指南:https://www.modelscope.cn/doc***odels/download
· --weight-format:量化精度,可以选择fp32,fp16,int8,int4,int4_sym_g128,int4_asym_g128,int4_sym_g64,int4_asym_g64
· --group-size:权重里共享量化参数的通道数量
· --ratio:int4/int8权重比例,默认为1.0,0.6表示60%的权重以int4表,40%以int8表示
· --sym:是否开启对称量化
此外我们建议使用以下参数对运行在NPU上的模型进行量化,以达到性能和精度的平衡。
optimum-cli export openvino --model <model id> --task text-generation-with-past --weight-format int4 --sym --group-size -1 --backup-precision int8_sym --trust-remote-code <model_dir >
这里的--backup-precision是指混合量化精度中,8bit部分的量化策略。
第三步,模型部署
目前我们推荐是用openvino-genai来部署大语言以及生成式AI任务,它同时支持Python和C++两种编程语言,安装容量不到200MB,支持流式输出以及多种采样策略。
· GenAI API部署示例
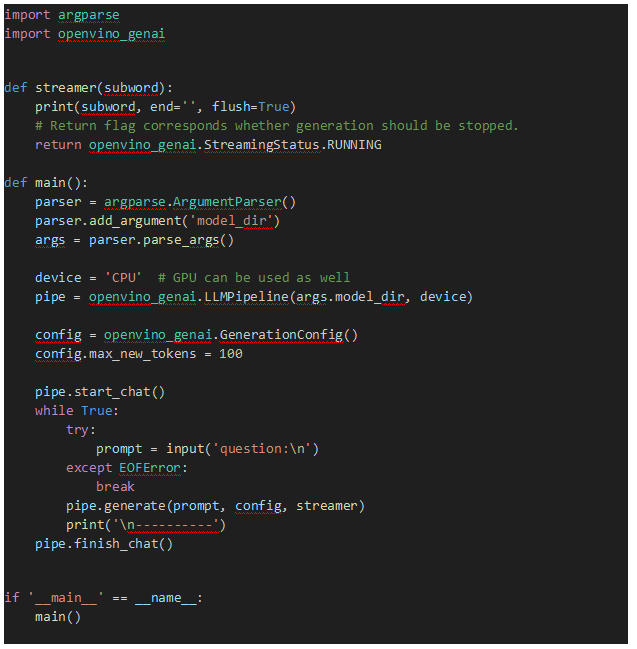
openvino-genai提供了chat模式的构建方法,通过声明pipe.start_chat()以及pipe.finish_chat(),多轮聊天中的历史数据将被以kvcache的形态,在内存中进行管理,从而提升运行效率。
chat模式输出结果示例:

总结
可以看到,利用openvino-genai,我们可以非常轻松地将转换后的MiniCPM 4.0模型部署在Intel的硬件平台上,从而进一步在本地构建起各类基于LLM的服务和应用。
参考资料
· openvino-genai 示例:https://github.com/openvinotoolkit/openvino.genai/blob/master/samples/python/text_generation/chat_sample.py
· llm-chatbot notebook示例: https://github.com/openvinotoolkit/openvino_notebooks/tree/latest/notebooks/llm-chatbot
· openvino-genai仓库: https://github.com/openvinotoolkit/openvino.genai
· 魔搭社区OpenVINO™专区:https://www.modelscope.cn/organization/OpenVINO
· OpenVINO™ Model Hub:https://www.intel.com/content/www/us/en/developer/tools/openvino-toolkit/model-hub.html