親愛的我把AI模型縮小了- 模型減量與壓縮技術簡介
 openlab_4276841a
更新于 2年前
openlab_4276841a
更新于 2年前
作者:英特尔边缘计算创新大使 許哲豪 博士
1989年科幻电影《亲爱的,我把孩子缩小了》,2015年「蚁人」,2017年「缩小人生」,以及我们从小看到大的多啦A梦「缩小灯」、「缩小隧道」,都不约而同的提到一个概念,就是可以通过一种神奇的机器,就能把人的体积大幅缩小但生理机能完全不减。 这里姑且不论是否符合物理定律,但如果真的能实现,就会像「缩小人生」中所提到的,可大幅减少地球资源的浪费,大幅改善人类的生存环境。 虽然以上提及的技术可能我们这辈子都难以看到实现的一天,但把超巨大的AI模型缩小但仍保持推论精度不变,还是有很多方法可以达到的。 接下来我们就来帮大家简单介绍一下几种常见技术。
1.AI模型组成元素
回顾一下本专栏三月份文章[1]第1小节提及的神经网络架构,其组成内容主要包括神经元内容(包含数量)、网络结构(神经元连接拓扑)及每个链接的权重值,如Fig. 2所示。 简单的卷积神经网络(CNN)如LeNet-5,就有约6万个权重,而大型模型VGG16则有约1.38亿个权重,到了现在流行的大型语言模型GPT-3已激激增到1750亿个权重,更不要说像GPT-4已有超过一兆个权重。通常在训练模型时为了精度,权重值大多会使用32位浮点数(FP32)表示法[2],这就代表了每个权重占用了4个Byte(32bit)的储存(硬盘)和计算(随机内存)空间。 这还不包括在推论计算过程中额外所需的临时随机内存需求。
为了让运行时减少数据(网络结构描述及权重值)在CPU和AI加速计算单元(如GPU, NPU等)间搬移的次数,所以通常会一口气把所有数据都都加载专用内存中,但一般配置的内存数量都不会太多,大约1GB到16GB不等,所以如果没有经过一些减量或压缩处理,则很难一口气全部加载。

Fig. 1 AI模型主要元素示意圖。
2. 常见压缩及减量作法
如同前面提到的,我们希望将一个强大复杂的AI模型减量、压缩后,得到一个迷你、简单的模型,但仍要能维持原有的推论精度或者只有些微(0%到指定%)的下降,就像我们平常看到的JPG影像、MP4影片,虽然采大幅度破坏性压缩,但人眼是很难分辨其品质差异的。 这样可以得到几项好处,包括大幅减少存储空间和计算用内存,推论速度加快,耗能降低,同时更有机会使用较低计算能力的硬件(如GPU变成CPU)来完成推论工作。 以下就把常见的四种方式简单介绍给大家。2.1 量化
通常在训练模型时,为求权重有较宽广的数值动态范围,所以大部分会采用32位浮点数(FP32, 符号1 bit,指数8 bit,小数23 bit,共4 Byte,数值表示范围 ±1.18e-38 ~ ±3.40e38)[2]。 而经许多数据科学家实验后,发现在推论时将数值精度降至16位浮点数(FP16, 2 Byte, -32,768 ~ +32767),甚至8位整数(INT8, 1 Byte, -128 ~ +127)、8位浮点数(FP8, e5m2, e4m3, 1 Byte)在推论时其精度下降幅度可控制在一定程度内,同时可让储存空间和内存使用量减少1/2到3/4,若加上有支持SIMD或平行运算指令集[1]还可让运算量提升1.x ~ 3.x倍,一举多得。以FP32量化为INT8为例,一般最简单的作法就是把所有空间等比对称分割再映射,不过当遇到权重值分配往单边靠或集中在某个区间时就很难分别出细部差异。 于是就有以最大值与最小值非对称方式来重新映射,以解决上述问题。
这样的量化减量的方式最为简单,但也常遇到模型所有层用同一数值精度后推论精度下降太多,于是开始有人采混合精度,即不同层的权重可能采不同数值精度(如 FP32,FP16,INT8 等)来进行量化。 不过这样的处理方式较为复杂,通常需要一些自动化工具来协助。
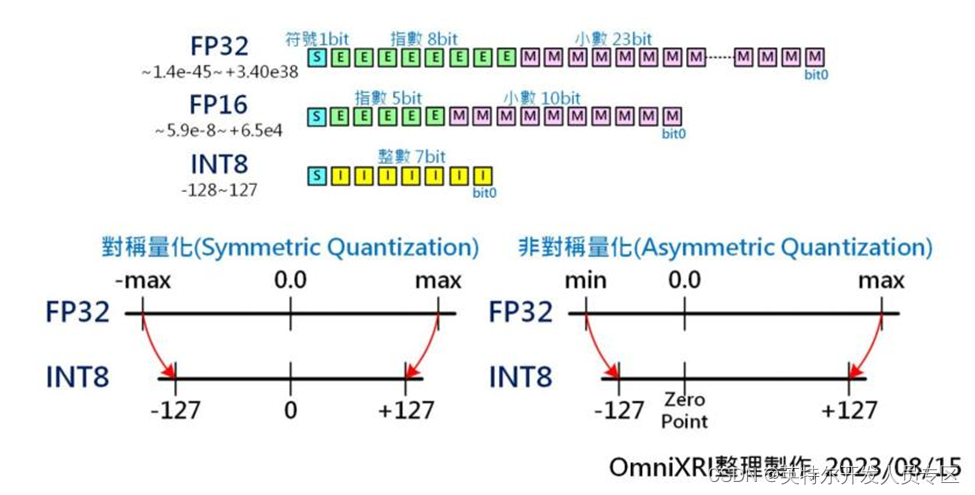
Fig. 2 權重值量化示意圖[3]。
2.2 模型剪枝(Pruning)
所谓树大必有枯枝,模型大了自然有很多链接(权重)是没有存在必要的或者是删除后只产生非常轻微的影响。 如果要透过人为方式来调整(删除、合并)数以百万到千万的连结势必不可能,此时就只能透过相关程序(如Intel OpenVINO, Nvidia TensorRT,Google TensorFlow Lite等)使用复杂的数学来协助完成。经过剪枝后,计算量会明显下降,但可以减少多少则会根据模型复杂度及训练的权重值分布状况会有很大差异,可能从数%到数十%不等,甚至运气好有可能达到减量90%以上。
另外由于剪枝后会造成模型结构(拓扑)变成很不完整,无法连续读取,所以需要另外增加一些描述信息。 不过相对权重值占用的储存空间,这些多出来的部份只不过是九牛一毛,不需要太过在意。
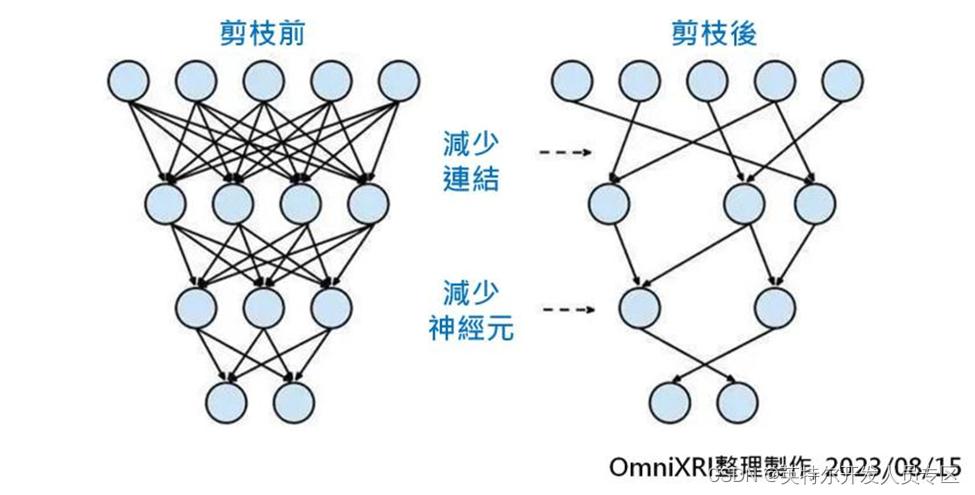
Fig. 3 模型剪枝示意图[3]。
2.3 權重共享(Weight Share)
由于权重值大多是由浮点数表示,所以若能将近似值进行群聚(合并),用较少的数量来表达,再使用查表法来映射,如此也是一个不错的作法。 但缺点是这样的作**增加一些对照表,增加推论时额外的查表工作,且由于和原数值有些微差异,因此会损失一些推论精度。如Fig. 4所示,即是将16个权重先聚类成4个权重(索引值),再将原本的权重值变成索引号,等要计算时再取回权重值,这样储存空间就降到原本的1/4。

2.4 知识蒸餾(Knowledge Distillation)
知识蒸馏基本上不是直接压缩模型,而是利用一个小模型去学习大模型输出的结果,间接减少模型的复杂度、权重数量及计算量。 大模型就像老师,学富五车,经过大数据集的训练,拥有数百万甚至千亿个权重来帮忙记住各种特征。 而小模型就学生,上课时间有限,只能把老师教过的习题熟练于心,但若遇到老师没教过的,此时是否能举一反三,顺利答题就很难保证了。如Fig. 5所示,训练学生模型时,将同一笔数据输入到老师模型和学生模型中,再将老师的输出变成学生的标准答案,学生模型再以此调整所有权重,使输出推论结果和老师一样即可。 当给予足够多及足够多样的样本训练后,学生就能结束课程,独当一面了。
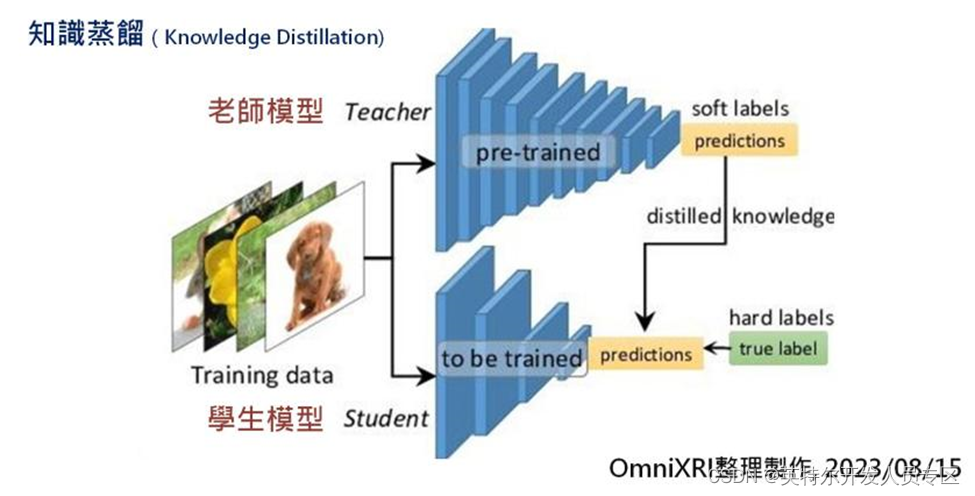
Fig. 5 知識蒸餾示意圖[3]。
小结
以上仅是简单介绍了部份减量及压缩模型的方式,还不包含模型减量、压缩后造成的精度下降如何调整。 这些工作相当复杂,只能交给专业的工具来办,其中 Intel OpenVINO Toolkit 就有提供许多模型优化(Model Optimization)[4]及神经网络压缩工具 NNCF (Neural Network Compression Framework)[5],有兴趣的朋友可以自行了解一下,下次有机会再为大家做更进一步介绍。参考文献
[1] 许哲豪,【vMaker Edge AI专栏 #03 】 AI芯片发展历史及最新趋势
https://omnixri.blogspot.com/2023/03/vmaker-edge-ai-03-ai.html
[2] 许哲豪,【vMaker EDGE AI专栏 #02】 要玩AI前,先来认识数字系统
https://omnixri.blogspot.com/2023/02/vmaker-edge-ai-02-ai.html
[3] 许哲豪,NTUST Edge AI Ch6-3 模型优化与布署─模型推论优化
https://omnixri.blogspot.com/p/ntust-edge-ai-ch6-3.html
[4] Intel, OpenVINO Toolkit – Model Optimization Guide
Model Optimization Guide — OpenVINO™ documentation
[5] Intel, Github – openvinotoolkit / nncf – Neural Network Compression Framework (NNCF)
GitHub - openvinotoolkit/nncf: Neural Network Compression Framework for enhanced OpenVINO™ inference
0个评论