【Notebook系列第四期】10分钟快速上手基于OpenVINO的文字检测
 openlab_4276841a
更新于 3年前
openlab_4276841a
更新于 3年前
从“14行代码就能实现视觉分类检测应用”
到“基于OpenVINO的视觉语义分割”,
Ethan老师携手Nono已经走完了三期课程
不知道大家是否已经快速上手?
疫情逐渐好转,
希望小伙伴们也能和Nono一样支棱起来
继续和Ethan老师走进第四期课程~

本期课程目标是
通过OpenVINO的python函数接口
完成一个简单的文字检测任务。
首先打开jupyter notebook,进入第四个课程章节中,在这里已经预设了一系列实验素材。
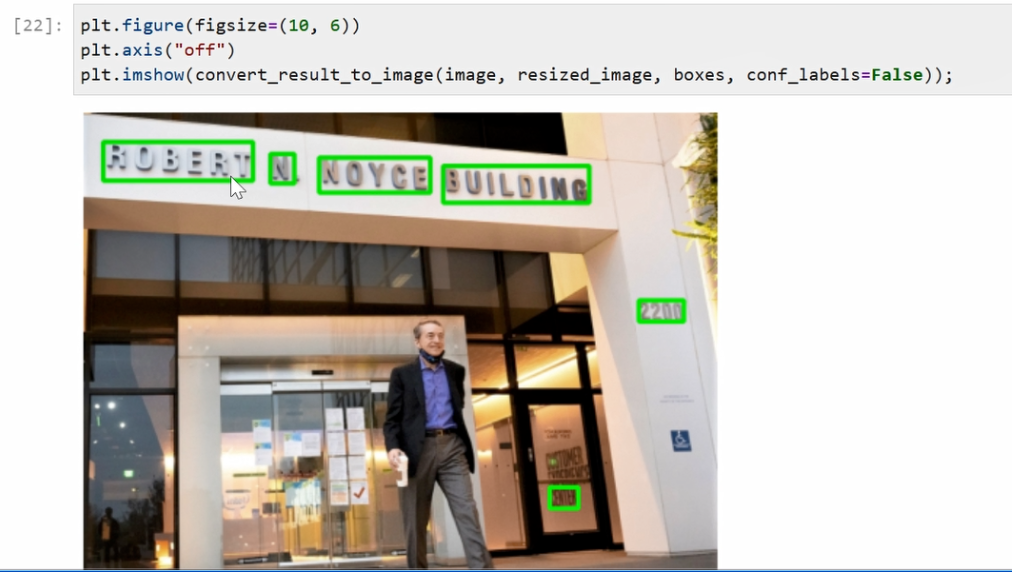
可以看到,在 data目录下有一个用于测试的图片,Ethan老师会针对这张图片中的文字对它进行检测。
其次在 model目录下已经提供了OpenVINO的预训练模型,这个预训练模型是由一个.xml和一个.bin文件所构成的。通过这个demo说明,可以看到 demo中用到的预预训练模型来自于Open Model Zoo中,同时这是一个基于横向文字的检测模型,它的输出是由100×5的矩阵所构成,其中“100”代表这个模型最大支持检测的物体数量是100,“5”代表着它的输出对目标的定位和它的进度信息,它的成员包括x轴的最小值,y轴的最小值,x轴最大值和y轴最大值,最后是通过置信度完成对它的封装。
课程开始和Nono一起学
首先进入代码运行环节。我们需要先来导入函数库,然后通过IE接口导入模型,导入以后,需要将模型的输入和输出信息提取到input_layer_ir和output_layer_ir对象中,我们需要从这两个对象中分别获取一些输入和输出的维度信息或者是shape信息,以便针对性的做一些前后处理的应用。
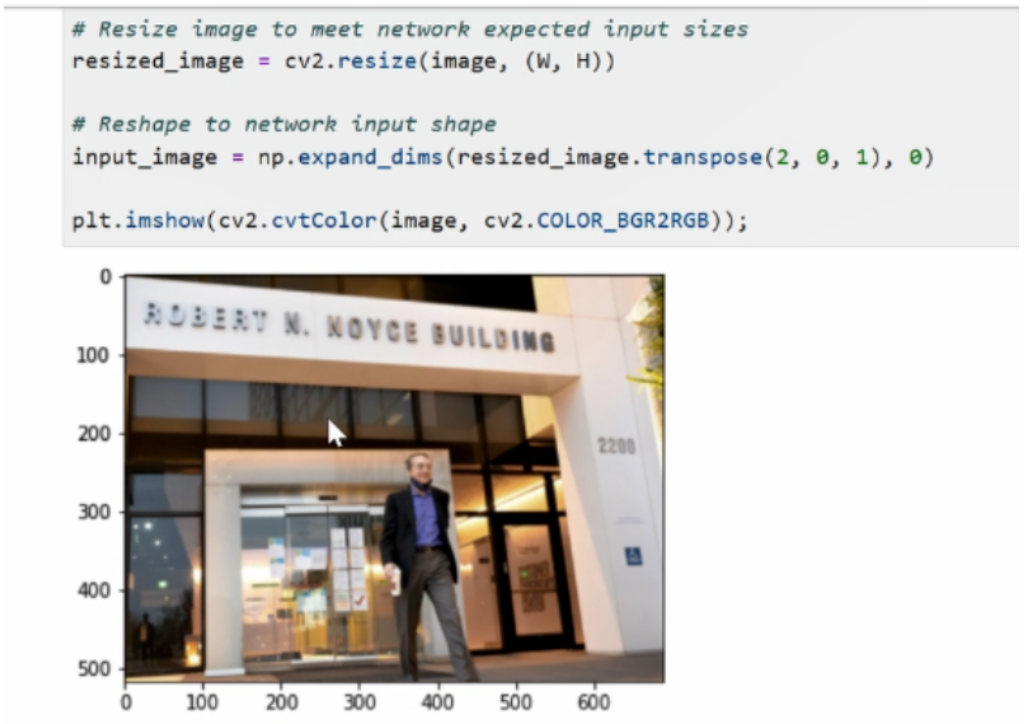
完成了模型载入以后,接下来我们导入测试图片或者叫输入图片,并进行预处理。
预处理:
首先用Open CV对其进行读取,然后通过Open CV对图像进行resize操作,而resize中用到的宽度和高度信息,就是从我们之前通过input_layer_ir对象里的shape所获取的模型。对于输入数据的尺寸要求,我们需要和常规操作一样将这个原始图像通过转置,然后添加batch size的维度,让它来符合我们对于模型输入数据格式的要求。最后打印一下这个数据,可以看到输入图片已经被resize到我们指定的长宽范围了。
重新运行一下代码。结束清空处理后,需要将这个输入图片送到compiled_model的对象函数中,并进行推理,推理过程中可以进行简单的打印。可以看到我们的输入数据跟刚刚一样,是有一个100×5的array构成的,其中真的有效的array就只有其中前面一部分,后面一部分是由无效的0所构成的。
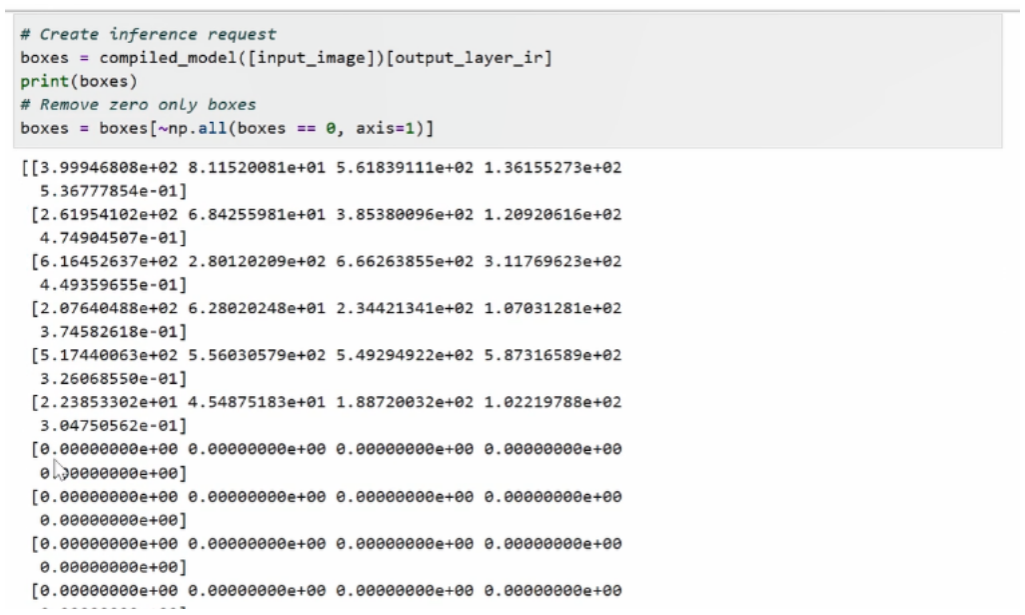
为了在做后处理的过程中,能减少后处理的计算量或者运算量,我们需要剔除掉这些无效数据。剔除也是同理,我们通过np.all这个函数来判断,哪些成员是由0构成的,然后把这些成员是0的无效数据统统给它给删除掉,然后形成一个新的boxes array。
当我们完成推理并获取结果数据以后,还需要对结果进行后处理,从而让它映射到真正的图片影像中,也就是做一个画框的操作。我们需要事先去定义一个叫covered_results_to_image的函数。这个函数由原始的bgr图片、resized以后的图片,以及我们这个结果数据所构成。

第一步是需要先去定义一个颜色,这个颜色为红色是为了去做置信度的标注,绿色是为了做bounding box的标注。
然后,我们需要获取resized以后的图片相对原始图片的缩放比例,这个缩放比例也会用于在还原真实坐标系的时候,对它的坐标体系进行映射。这边我们用到了 ratio_x和ratio_y来表示真实的x轴比上resized以后的x轴的比率。ratio_y也是同理。
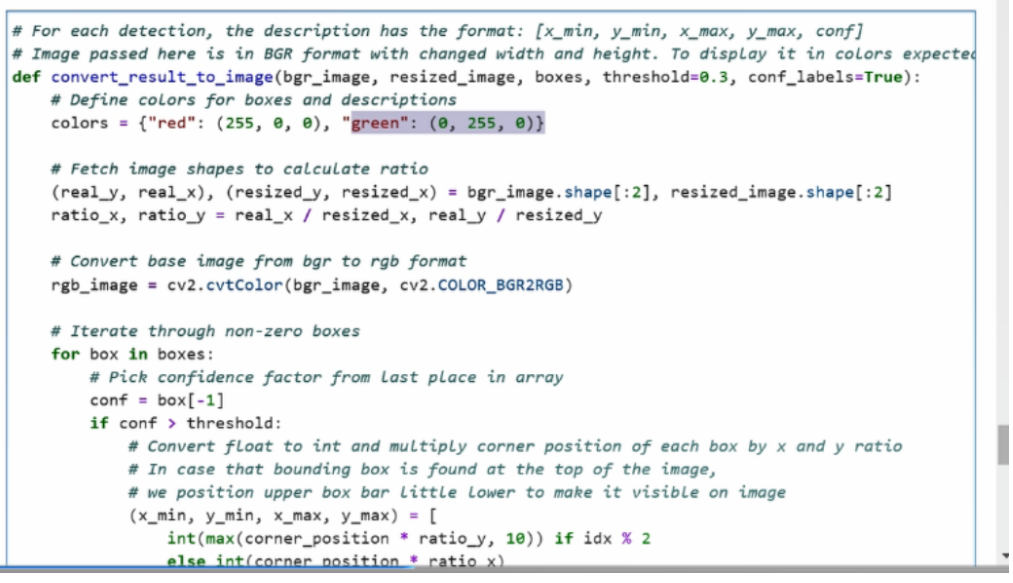
考虑到操作中会用到 plt工具, plt工具做图像演示的时候,需要以rgb格式进行输出。所以接下来,我们会对原始的bgr图片做一个bgr转rgb的操作。
结果数据处理和Nono一起学
现在正式来到了我们结果数据的处理的环节中。我们首先去遍历我们所有的box,获取每一个box对象,这里box对象最后一个成员也就是置信度。
我们需要通过预先设置的阈值,过滤掉一些置信度比较低的 bounding box,得到满足我们要求的bounding box以后,我们会对bounding box进行映射还原,将它从 resized以后的图像的坐标系中还原到真实的 image坐标系中。除此之外,我们可以采用枚举的方式,将 x轴的信息和y轴的信息分别还原。
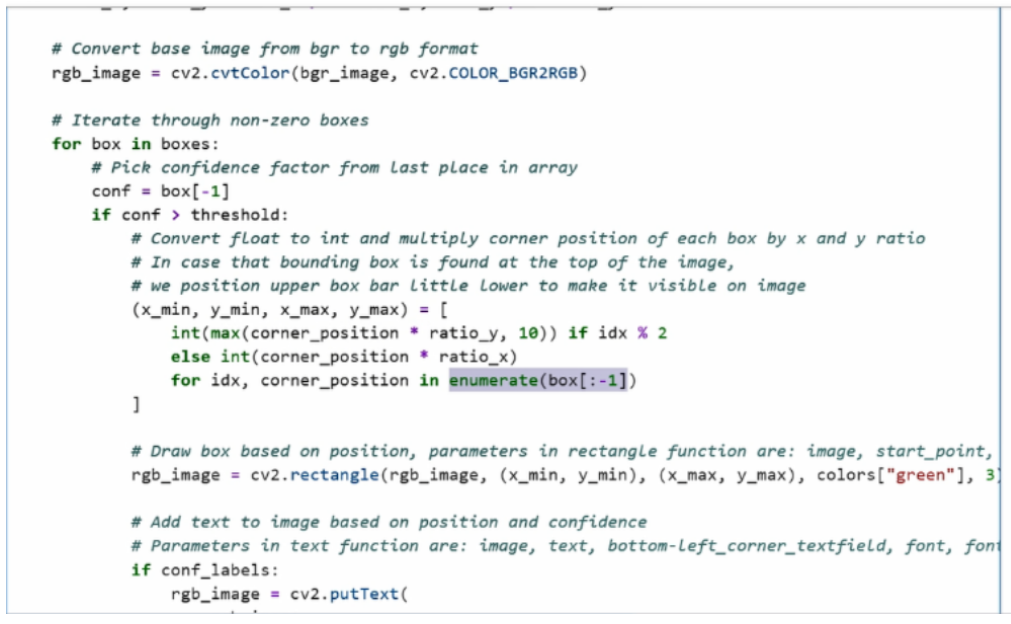
大家也可以注意到,在还原y轴信息的时候,我们会做一个比较。考虑到有些bounding box位置太高可能会存在触顶操作,所以y轴的值会非常大,以至于我们可能看不到bounding box具体的边。所以为了更好的去展示bounding box的位置,我们需要去对一些位置过高的对象进行上限设置,这里上限就设了一个10,所以如果y的值或低于10,我们通通会输出10作为它的值的取代。
得到了在真实坐标系以后的 x mini、y mini和x max和y max映射以后,我们接下来可以通过Open CV的rectangle函数去画框,框的颜色也会预先由我们定义好的green作为画框颜色,画框的对象也是刚才转化好以后rgb的原始图像。
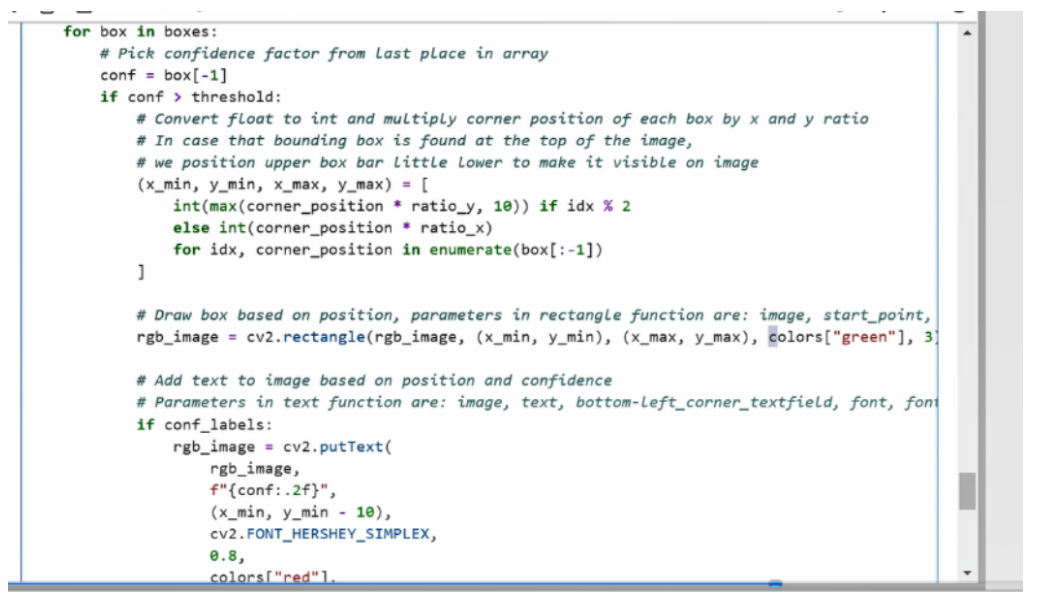
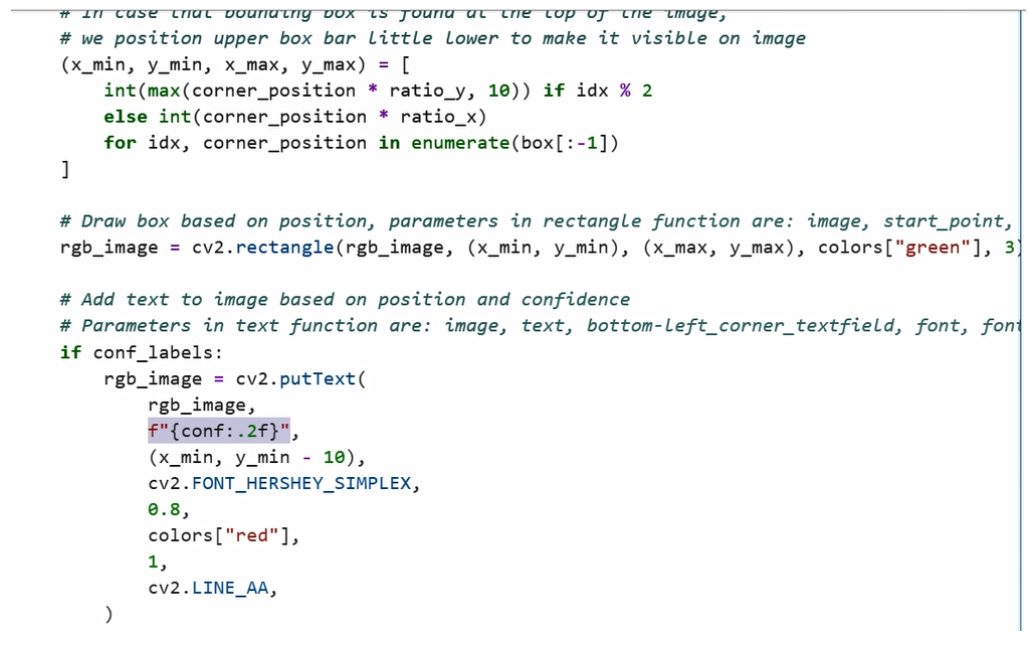
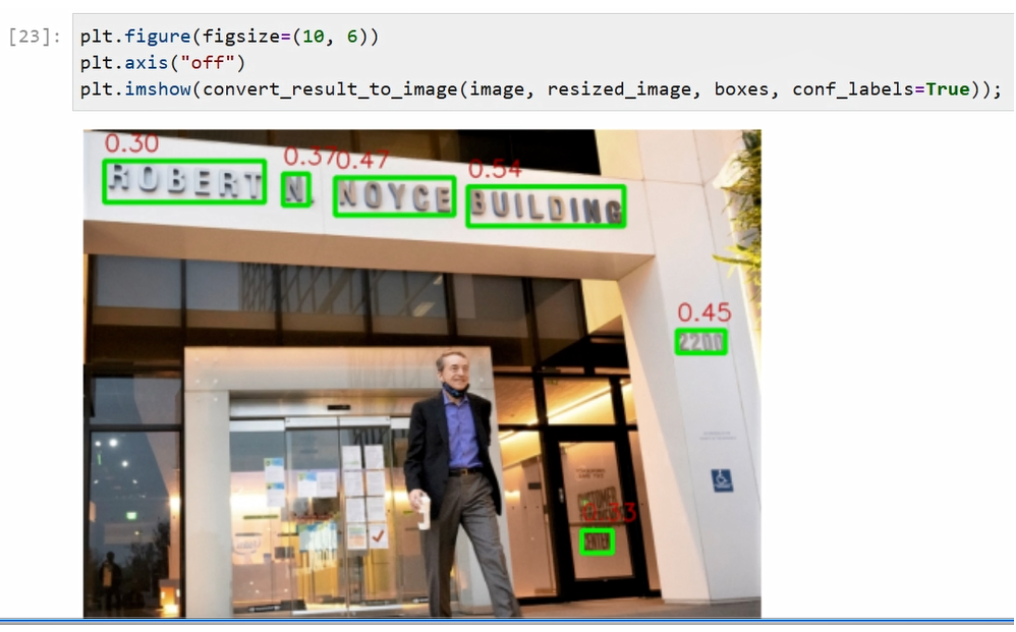
完成画框以后,如果大家想去在框上再标注一些置信度,也可以通过Open CV的putText函数完成。我们会通过这个方法去打印置信度信息,并在框上进行标记,然后返回我们打完标志画完框的图像数据,
最后我们运行一下这个函数的定义,然后跑一下代码。可以看到我们事先预先设定好了plt的框的大小,是在10x6的范围,去掉坐标系。然后我们通过刚才预先定义好的convert_result_to_image函数去获得一个带标注的图像对象,接下来我们通过plt.imshow对其进行展示,可以看到图像中的所有的文字都被标以绿框被得到准确的识别。我们将其改成True以后,每一个框置信度也可以同步得到展示,可以看到不光有绿色的框,同时每个对象上面也打印了红色的置信度,代表每一个框的它的一个可能性的大小。
本文转自微信公众号【OpenVINO 中文社区】